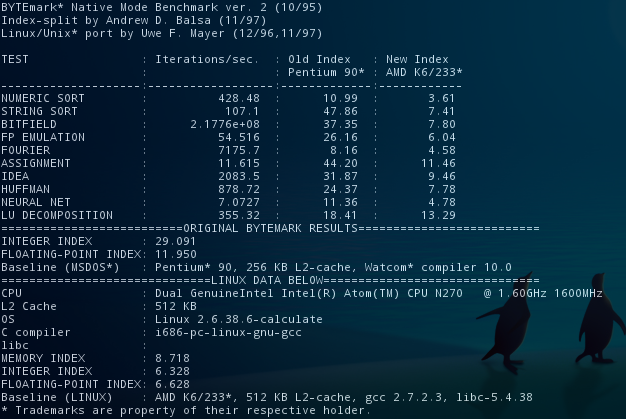
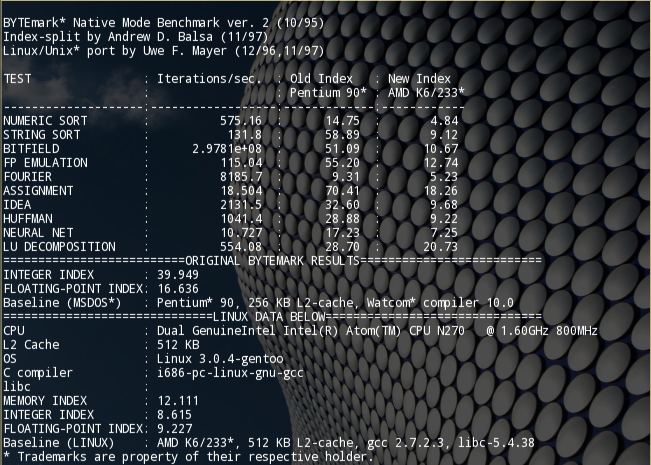
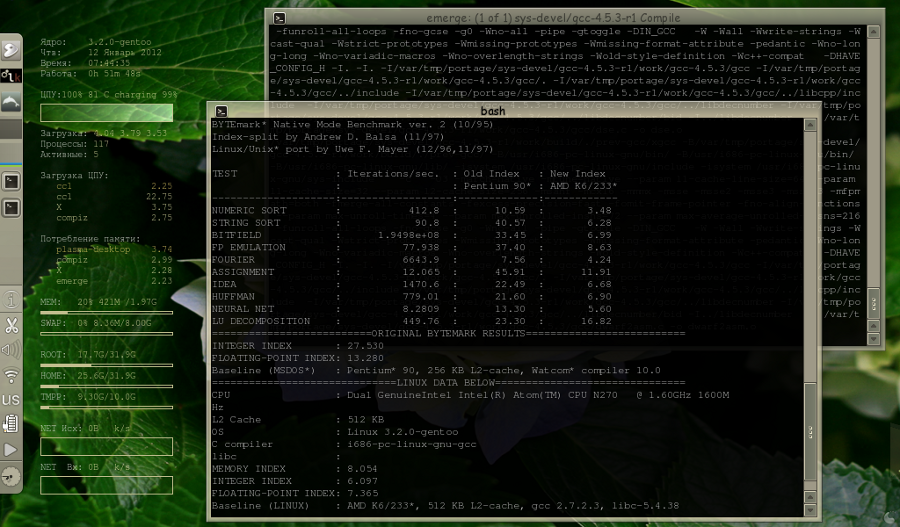
Вот три снимка замера производительности с помощью теста nbench:
1.Тест nbench на бинарной версии дистрибутива
2.Тест nbench на оптимизированной системе
3.Тест на оптимизированной системе, когда в фоне запущена компиляция gcc в 3 потока
Все замеры произведены на нетбуке asus n10j.
Какой из этого напрашивается вывод?
Фактически, оптимизировав систему один раз, мы получаем компиляцию и установку любого пакета без затрат - этот кусок производительности мы уже отвоевали. А в остальное время на системе чистый профит.
Минус у компиляции из исходников единовременного характера - нужно 1 раз потратить время и настроить систему под конкретную конфигурацию железа. Для компаний с разношерстным железом это обычно неприемлемо. Но для конечного пользователя вполне осуществимая задача. Примерно через полгода средний пользователь генту систем уже приобретает достаточный опыт для самостоятельного проведения этой “хирургической” операции на своем компьютере.
Calculate Linux, с моей точки зрения, оптимально подходит не только для бизнеса, но и для домашней системы.
1.Легко установить
2.Документация на русском языке - не сложно освоить
3.Проверенное профессионалами программное обеспечение
4.Качественная поддержка как со стороны разработчиков, так и сообщества пользователей
5.После приобретения навыков, можно максимально оптимизировать свою систему
Хотя сравнения с Pentium90 и K6, конечно вставляют. Кстати, а почему цыфры для этих процов разные на разных системах, это же должен быть “эталон”?
“Оптимизированная” система это пересобранная небинарно калька или, все же, собранная гента?
А какая калька использовалась?
Да, и обоина из win7 на линуксе, смотрится конечно диковато.
Хотя сравнения с Pentium90 и K6, конечно вставляют. Кстати, а почему цыфры для этих процов разные на разных системах, это же должен быть “эталон”?
Ориентируюсь по первому столбцу - цифры для Pentium90 и K6 меня мало заботят. Но вероятно это как-то связано либо с частотой, либо с другими различиями в процессорах. Исходники не анализировал.
“Оптимизированная” система это пересобранная небинарно калька или, все же, собранная гента?
Все равно. У меня сейчас обе системы. Генту ставил чтобы получить независимое сравнение. Производительность обеих систем после оптимизации равнозначна. Если очень хочется могу снимок экрана с тестом производительности сделать и из кальки. Но разница будет настолько смешная, что это не назовешь даже погрешностью.
А какая калька использовалась?
Пока установлена CLD версии 11.3
Да, и обоина из win7 на линуксе, смотрится конечно диковато.
Настраивал цветопередачу на новом ноутбуке с виндой, купленного взамен утраченного в бою с наушником. А у него, как выяснилось, напрочь отсутствуют нормальные профили icc - отсюда и картинка для окончательного сравнения результатов настройки.
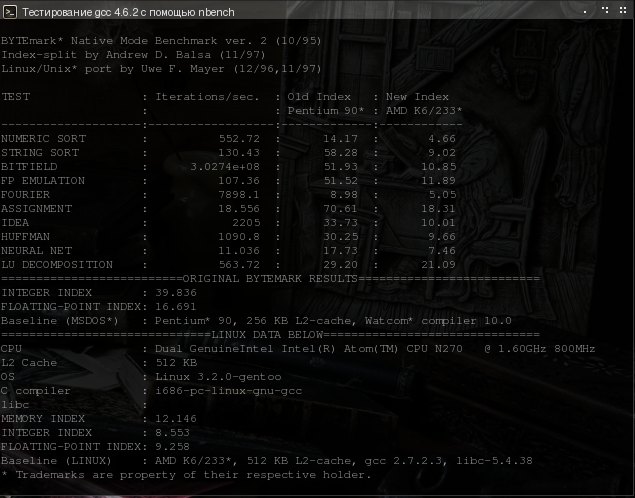
Перед пересборкой мира с какими-либо параметрами, сначала отшлифуйте их на тестовых программах, которые наиболее приближены к целевому использованию компьютера. Я, не сильно заморачиваясь, тестировал ключи перекомпиляцией бенчмарка nbench. Компилируется быстро и на тест 4 минуты примерно. А что главное - сразу видно какие параметры выгодны, а какие нет.
Алгоритм прост:
1.По времени компиляции бенчмарка, именно по времени компиляции(!), выявляем медленные ключи чуть ускоряющие работу незначительного количества программ, но сильно замедляющие компиляцию.
2.По результатам теста бенчмарка определяем эффективность параметра.
3.Решаем нужен ли нам ключ или нет.
P.S.
От себя желаю удачной настройки и предлагаю делится ключами оптимизации с указанием процессора, компилятора, результатов тестов, ключей оптимизации. Предлагаю обсудить состав бенчмарков для контроля результатов оптимизации. Это поможет сэкономить время и не изобретать велосипед каждый раз повсеместно. И, возможно, появится статистика, которая позволит выявить дополнительные ключи, положительно влияющие на производительность всех процессоров на конкретных компиляторах.
К сожалению, ключи пока подобраны не оптимально, так как на некоторых тестах результат хуже чем, при обычной оптимизации. При более оптимальных, результаты могут получится еще более убедительными. При подборке параметров важно найти такие, которые, не замедляя других тестов, будут повышать производительность. Тогда даже включение параметра -ffast-math практически не будет увеличивать производительность приложений.
-Ofast, если не ошибаюсь добавляет к -O3 только ключ -ffast-math.
P.S.
Очень сильно влияет компилятор. Ofast появился с версий 4.6, но вплоть до 4.6.1 включительно точно не рулил у меня тестировал достаточно тщательно.
компилятор 4.6.2. Действительно, главная “приправка” Ofast -ffast-math. Но кроме него задействована комбинация опций. В доках так слегка упоминается. Но поведение разительно по сравнению с 4.6
При других, тестируемых комбинациях, иногда либо сильно заваливались некоторые тесты, либо ключи не оказывали заметного влияния. Проседание наблюдалось до 40% по отдельным тестам. Кстати разница между -Ofast и -O3 -ffast-math всего в 5 ключей. Их отмена (-fno-compare-elim -fno-ipa-profile -fno-tree-bit-ccp -fno-devirtualize и -fno-partial-inlining) на компиляторе gcc 4.6.2 не дала возможности приблизится к результатам gcc 4.5.3. Ключ -mfpmath=both выдает худший результат, чем -mfpmath=sse. Компилятор gcc 4.6.2 более менее вырвался вперед только на тесте IDEA, но это ~3,5%…
Для атома пока рулит все же gcc 4.5.3, но уже с заметно меньшим отрывом от gcc 4.6.2 по сравнению с версиями 4.6.0 и 4.6.1
Побаловался я этим и понял, что та электроэнергия спаленая компом при компилляции (и та последущая при обновлении системы) и то время которое было потрачено не стоят того прироста производительности
Побаловался я этим и понял, что та электроэнергия спаленая компом при компилляции (и та последущая при обновлении системы) и то время которое было потрачено не стоят того прироста производительности
… Например, человеку, печатающему со скоростью 300 орфографических ошибок в минуту никакая оптимизация ничем не поможет, грамотности не прибавит. Тут нужна оптимизация мозга.
Побаловался я этим и понял, что та электроэнергия спаленая компом при компилляции (и та последущая при обновлении системы) и то время которое было потрачено не стоят того прироста производительности
Всем известно, что баловство до хорошего не доводит…
Шутки в сторону, поздравляю!) Но хотелось бы понимать как Вы сумели опровергнуть аксиому в утверждении, что “Фактически, оптимизировав систему один раз, мы получаем компиляцию и установку любого пакета без затрат - этот кусок производительности мы уже отвоевали. А в остальное время на системе чистый профит”.
Есть всего три случая, когда дополнительная оптимизация реально не принесет пользы:
1.Дистрибутив изначально сделан под Ваш, а не усредненный процессор
2.Срок использования вещи или период пользования чрезвычайно малы
3.Техника используется не по прямому назначению
Отсюда можно сделать вывод, что у Вас или Pentium Pro или Вы собираетесь либо выкинуть комп через месяц-другой, либо используете его крайне редко или компьютер служит тумбочкой, подставкой, просто украшением интерьера. Других вариантов не наблюдаю. Али не прав?)) Предлагаю подумать перед ответом.
Спасибо за ссылки, интересная статья. Но прошу без обид.
Но, возможно к моему предыдущему сообщению надо было добавить слово “для сред. статистического десктопа”.
И что я иммею ввиду под затратой электроэнергии и времени относится не к самому процессу оптимизации. А к тому что все последущие апдейты системы должны выполнятся не бинарными пакетами а исходниками. Иначе мы теряем всю нашу оптимизацию.
Так вот все эти последущие апдейты и кушают время и электроэнергию (по сравнению с бинарным апдейтом) посколько нагруженный проц кушает больше… а еще и монитор вывести из спящего режима чтобы посмотреть как компиляция идет (еще плюс 90Ватт на некоторое время)…
у меня система пересобиралась около 16 часов (1100 с чемто пакетов)… и то точно не знаю бо прерывалась на 3х пакетиках и я выключал комп.
Ну а когда апдейты, кол-во пакетов тоже не малое…
Ну не будем дальше… а то трейд технического характера а я тут философию развел
П.С. проц i5 661 3.3Ghz.
а задачки у компа то простые, домашние… кино посмотреть, бухгалтерию ввести, посерфить веб, dynamips погонять, ну и на бирже поторговать… вот пожалуй и все…
П.С. проц i5 661 3.3Ghz.
а задачки у компа то простые, домашние… кино посмотреть, бухгалтерию ввести, посерфить веб, dynamips погонять, ну и на бирже поторговать… вот пожалуй и все…
Да какие обиды, все ясно. ну, тогда и напрягаться не стоит…